What Entropy tells us about Data Compression
Part I: Concepts
Introduction
When we implement a data compression technique, one of the first questions we might ask is “how well does it work?” Looking at the ratio of the sizes for input versus output (the compression ratio) gives us a place to start. But the answer it provides is incomplete. The compression ratio depends as much on the nature of the input data as it does the effectiveness of the compression technique. A very simple input set – one that consists of a single data value repeated multiple times – will yield a high compression ratio for virtually any implementation. A complex data set, or one consisting of highly random values, may resist even the best compression techniques.
To understand the effectiveness of a compression technique, we need a way to assess the complexity of an input data set. One tool for doing so is provided by the information entropy metric introduced by Claude Shannon in his ground-breaking paper “A Mathematical Theory of Communication” (Shannon, 1948).
Entropy
In the 1940’s, Shannon developed a mathematically rigorous treatment of the problem of transmitting digital data over a noisy communications channel (Soni & Goodman, pg. 115). The resulting 77 page paper has been called “one of the great analytical achievements of the 20th century” (MIT, 2001). Its primary focus was establishing a mathematics-based framework for error-free communications. But, in doing so, the paper provided the theoretical underpinnings modern data compression. Part of that was the introduction of the concept of entropy. What was the lowest bound to which a data source could be encoded without a loss of information? Indeed, how could we even define the idea of information?
Shannon realized that the information content of a text could be quantified based on the idea of predictability. Consider a text consisting of a single character repeated many times. Since the value of the next symbol in the text is always known beforehand, it conveys no new information. Alternatively, consider a case where a text consists of a non-trivial symbol set and the selection of the next symbol in a sequence cannot be predicted with perfect certainty. Shannon demonstrated that each new symbol would contribute information based on the degree to which it was unpredictable. Shannon provided a way of quantifying this process using a metric he named entropy.
Shannon also demonstrated that the entropy metric represents the lowest bound to which a text could be compressed without loss of information. This result is known as the source coding theorem (Wikipedia 2024c). It applies in cases where a variable-length binary code is assigned to each unique symbol in an arbitrary text or sequence of numeric values. In such cases, the theorem allows us to use the entropy calculation as a way of evaluating the effectiveness of a data compression implementation.
Note: For an engaging and accessible explanation of the entropy concept, see Josh Starmer’s video Entropy (for Data Science) Clearly Explained!!! on YouTube (Starmer, 2024). I think you will find that the video lives up to its title
The entropy calculation
Let’s look at Shannon’s entropy calculation. Consider a
text to be a data set 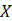 that consists of a set of unique values
that consists of a set of unique values
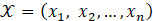 each occurring in the body of the text with a distinct probability
each occurring in the body of the text with a distinct probability
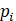 .
These values may be letters of the alphabet, numerical values for a raster data product, or
any information that can be serialized and encoded. For our purposes, we can
write Shannon’s entropy equation as
.
These values may be letters of the alphabet, numerical values for a raster data product, or
any information that can be serialized and encoded. For our purposes, we can
write Shannon’s entropy equation as
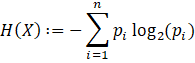
Because we are interested in digital applications, we use the log base 2 to obtain a value in bits. Shannon’s proofs and derivations use the log base e. In that form, the computation is unitless. Applying the log base 2, allows us to describe entropy in terms of a rate given in “bits-per-symbol”. Incidentally, the term “bits” was introduced in Shannon’s original paper. He attributed the term to J.W. Tukey (Shannon, pg. 1).
The concept of information entropy should not be confused with the idea from physics, though the equation above resembles Gibbs formula (Wikipedia, 2024a). Shannon himself claimed that he chose the term entropy based on the suggestion of John von Neumann (Soni & Goodman, pg. 162).
Applying entropy
To illustrate the entropy concept, let’s consider a couple of applications.
Natural language text: The probability for each symbol in the alphabet is computed based on the number of times it occurs in the text divided by the total number of symbols in the text. In western languages the vowel ‘e’ occurs more frequently than the character ‘q’. So the character ‘e’ has a high probability and the character ‘q’ a low probability. Using that approach to evaluate a text extract from this document produces an entropy value of approximately 4.79.
Numeric data: The most common way to compute entropy for numeric data is to treat individual bytes as symbols. Since a byte can take on 256 separate values (typically, 0 to 255), this approach limits the maximum number of unique symbols in a data stream and simplifies the process of counting symbols and computing probabilities. Shannon's definition of entropy is broad enough to accomodate symbol sets consisting of alternate data types, such as integers or even floating-point values. Examples of this approach are given in Part II of this article.
Higher order models for entropy and conditional probability
The entropy specification presented above does not consider the order of symbols. It treats the probability of any particular symbol as independent of the symbols that precede it. That formulation is often referred to as a first-order model. In practice, of course, the probability of finding a character in natural language text or a value in numeric sequences is often influenced by its predecessors. For example, in languages with Latin roots, the letter ‘q’ is generally followed by the letter ‘u’. So the probability of a particular letter having the value ‘u’ varies significantly depending on whether the previous letter was a ‘q’ (question, qu’est-ce que, queso, quindici, quem,…, quod erat demonstrandum).
Since Shannon’s original publication, investigators have established definitions for entropy that treat symbol sequences based on conditional probability. For example, the second-order model for entropy couples the probability of a particular symbol to the value of the symbol that preceded it.
Let ![]() be the conditional probability that the present symbol is the j-th entry in the symbol
set given that the previous symbol is the i-th symbol. Then the second-order entropy
can be computed as
be the conditional probability that the present symbol is the j-th entry in the symbol
set given that the previous symbol is the i-th symbol. Then the second-order entropy
can be computed as
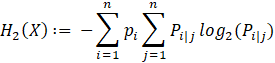
The second-order entropy for this document is 3.54. Higher-order computations follow the pattern shown
in the formula above. We can extend it for third-order entropy where
![]() is the conditional probability that the present
symbol is the k-th entry in the symbol set given that the previous two symbols
were the i-th and j-th entries
is the conditional probability that the present
symbol is the k-th entry in the symbol set given that the previous two symbols
were the i-th and j-th entries
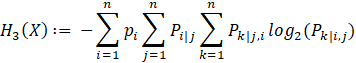
Entropy coding, the Huffman technique, and efficient data compression
The term entropy coding refers to "any lossless data compression method that "attempts to approach the lower bound declared by Shannon's source coding theorem" (Wikipedia, 2023). Entropy coding techniques include Huffman coding, arithmetic coding, and asymmetric numeral systems. The simplest and most widely used of these is Huffman coding.
Huffman coding
Huffman coding (Huffman, 1952) uses variable-length bit sequences to encode individual entries in a symbol set (alphabet, etc.). The encoding for each symbol is based on the frequency of its occurrence within the text. The most common symbols are assigned short sequences. Less common symbols are assigned longer sequences. Since Huffman coding does not consider the order of symbols within a text, the first-order entropy equation is sufficient to provide a lower bound for its compressed output.
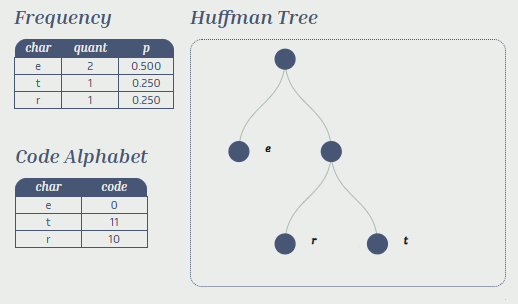
The Huffman coding technique can be conceptualized as a binary tree. The process for decoding a bit sequence begins with the root node of the tree and traverses left or right depending on the value of each bit in the encoded sequence. When the process reaches a terminal node (a “leaf” node), the symbol associated with the node is added to the decoded text.
Figure 1. below shows the Huffman tree constructed for the text “tree”. The probabilities for various symbols are shown in the ‘p’ column in the frequency table (note that they are all negative powers of 2). The structure of the Huffman tree is determined based on the computed probabilities for each symbol in the text. The letter ‘e’ occurs most frequently, so is assigned a shorter sequence than ‘t’ or ‘r’. The bit sequence for the encoded text is 111000.
Implementation details and overhead
Of course, if we wish to use Huffman coding to compress a data set, we will also want to have some method to extract the original information later on. So, most Huffman compressors include some method to encode the structure of the Huffman tree. This requirement adds overhead to a compressed product. Even discounting the overhead, the Huffman code often does not reach the lower-bound established by the first-order entropy computation. This shortfall occurs because the Huffman coding can only represent probabilities as integral powers of two and must approximate the probabilties for many symbol sets. Even so, it usually produces good results.
In practice, we accept a Huffman implementation as efficient if it is close to the entropy value. One way to define efficiency is using the formula below:
For example, the Gridfour software project includes an implementation of Huffman coding. To evaluate it, we exported the text for an earlier version of this document to an 8-bit text file. Running the text through a first-order entropy computation and a Huffman coding implementation yielded the following results:
Huffman encoding
Length of text: 11813 bytes
Unique symbols in text: 88
Entropy: 4.79 bits/symbol
Huffman tree overhead: 887 bytes, 10.08 bits per unique symbol
Encoded size
Including overhead: 4.86 bits/symbol
Excluding overhead: 4.82 bits/symbol
Efficiency
Including overhead: 97.6 %
Excluding overhead: 99.4 %
For many data compression techniques, the efficiency calculation is useful as a diagnostic tool. A poor efficiency rating would indicate that there might be a problem with an implementation. Efficiency also has the advantage of being robust with regard to the magnitude of the entropy in the source data. If an implementation is suitable to a data set, even a data set with a high entropy value will produce a good efficiency score.
Beyond entropy coding: the Deflate algorithm
Because the Huffman technique does not consider the order of symbols within the text, it cannot take advantage of sequences of symbols such as those described in the section on second-order entropy above. More recent techniques, such as Lempel-Ziv and Deflate, improve data compression ratios by looking at repetitive groups of symbols occurring in a text.
The Deflate technique is used in the zip utility, the PNG image format, and in many other software products. It usually out-performs Huffman. In fact, the bits-per-symbol value for a Deflate compressed text is often lower than either the first or second-order entropy rates. For the sample text cited above, we have the following results:
First-order Entropy: 4.81
Second-order Entropy: 3.53
Deflate: 3.16
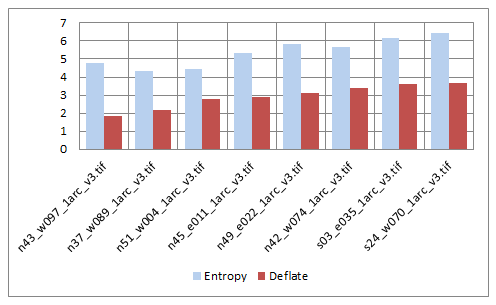
The entropy definition is not a good match for the process implemented for the Deflate technique. In fact, the bits-per-symbol averages obtained from Deflate may be less than the computed entropy rates. So, in the case of Deflate, the entropy rate does not represent a lower bound for the compression technique. Even so, there is often a loose coupling between the entropy for a data source and the relative size of Deflate-compressed product. The figure below compares bit rates for terrestrial elevation data taken from the Shuttle Radar Topography Mission (NASA, 2020). The original elevation data was stored as integer values in raster data files (TIFF format) without data compression. The Deflate technique was applied directly on the source data. And, while there is not a perfect relationship between the entropy and Deflate output, a general trend is clearly visible.
Conclusion
By providing insight into the complexity of a data source, the entropy metric provides a tool for evaluating the effectiveness of a data compression technique. Cases where the entropy rate indicates that a data compressor performs poorly may indicate opportunities for refining an algorithm or investigating the correctness of a particular implementation.
Case studies that explore how entropy relates to the compression characteristics of specific data sets are provided in Part II of this article.
References
Fano, R.M. (1949). The transmission of information. Technical Report No. 65. Cambridge (Mass.), USA: Research Laboratory of Electronics at MIT.
Huffman, D. (1952). A method for the construction of minimum-redundancy Codes. Proceedings of the IRE. 40 (9): 1098–1101. doi:10.1109/JRPROC.1952.273898.
MIT editors. (2021, July 1). Claude Shannon: reluctant father of the digital age. MIT Technology Review. Accessed from https://www.technologyreview.com/2001/07/01/235669/claude-shannon-reluctant-father-of-the-digital-age/
National Aeronautics and Space Administration [NASA]. (2020). Shuttle Radar Topography Mission (SRTM) https://www2.jpl.nasa.gov/srtm/ Data was downloaded from the USGS Earth Explorer web site at https://earthexplorer.usgs.gov/.
Shannon, C. (July 1948). A mathematical theory of communication (PDF). Bell System Technical Journal. 27 (3): 379–423. doi:10.1002/j.1538-7305.1948.tb01338.x. hdl:11858/00-001M-0000-002C-4314-2. Reprint with corrections hosted by the Harvard University Mathematics Department at https://en.wikipedia.org/wiki/Harvard_University (accessed November 2024).
Soni, J., & Goodman, R. (2017). A mind at play: how Claude Shannon invented the information age (First Simon & Schuster hardcover edition.). Simon & Schuster.
Starmer, J. [Stat Quest] (2024). Entropy (for Data Science): Clearly Explained!!! [Video]. YouTube. https://www.youtube.com/watch?v=YtebGVx-Fxw
Wikipedia contributors. (2023, November 15). Entropy coding. In Wikipedia, The Free Encyclopedia. Retrieved 18:06, November 27, 2024, from https://en.wikipedia.org/w/index.php?title=Entropy_coding&oldid=1185288022
Wikipedia contributors. (2024a, October 3). Josiah Willard Gibbs. In Wikipedia, The Free Encyclopedia. Retrieved 17:02, October 15, 2024, from https://en.wikipedia.org/w/index.php?title=Josiah_Willard_Gibbs&oldid=1249234374
Wikipedia contributors. (2024b, October 14). Huffman coding. In Wikipedia, The Free Encyclopedia. Retrieved 18:03, October 14, 2024, from https://en.wikipedia.org/w/index.php?title=Huffman_coding&oldid=1245054267
Wikipedia contributors. (2024c, May 2). Shannon's source coding theorem. In Wikipedia, The Free Encyclopedia. Retrieved 13:01, October 3, 2024, from https://en.wikipedia.org/w/index.php?title=Shannon%27s_source_coding_theorem&oldid=1221844320
Ydelo, A. (2021). Huffman coding online (Web Page). Accessed October 14 from https://huffman-coding-online.vercel.app